







Robust API
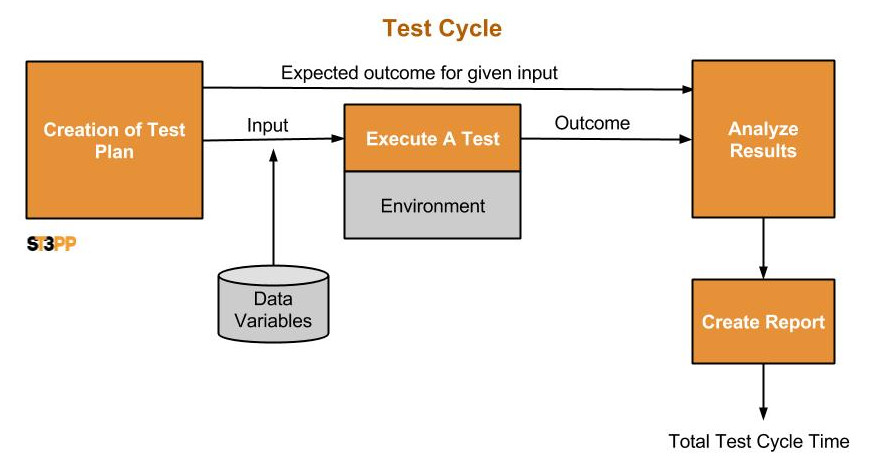
In the Data Economy, the currency is information. The near default method of accessing information today is via the developing and exposing of Web Services API as Providers of information. Most applications are developed to Consume more than 1 API, increasingly from more than one location, source and even organization. SaaS, cloud services, supply chains, payment clearing, shipping information, social media etc are all examples that rely on API’s. A good quality API is essential for success in the Data Economy and corporations need to define an approach to API quality in much the same way as they would any other product quality. ST3PP refers to this need for a strategy to ensure Robust and Sustainable API.
Traditional approach to development architecture, tightly coupled web services development with the application client development. Business gave requirements and developers created all the services to expose these requirements. Developers then developed the client UI to access these services. When they felt they were “done” they passed it to quality assurance, which tested the “application” as a whole via the client UI. Often manually entering keys into the client’s UI’s fields in an attempt to ensure functionality. If anything was identified by QA, it usually went back to development to “fix” and development decided if it was easier to be “fix” the service or the client. The next time business issued new requirements, the entire process started again.
In the Data Economy, the client application needs to be treated independent of the Web Service API. API’s are designed as re-usable components to stand independently of any client or other application that may Consume the API. The various API each Provide some portion of information witch the Client application may consolidate or refine. These API could come from multiple locations, organizations or delivery models, like SaaS, BYOD, Cloud, Open API etc . API are no longer something IT deals with, but considered as core business asset, differentiating one organization from the next in a competitive information based economy. Better API = Better ability to establish corporate value in the economic chain. To get the most form API assets, a new approach to development and QA is needed. API need to be treated independently, like an end product. Developing API to Provide information yet unknown future consumers, requires that API be Robust.
1) Functional Testing.
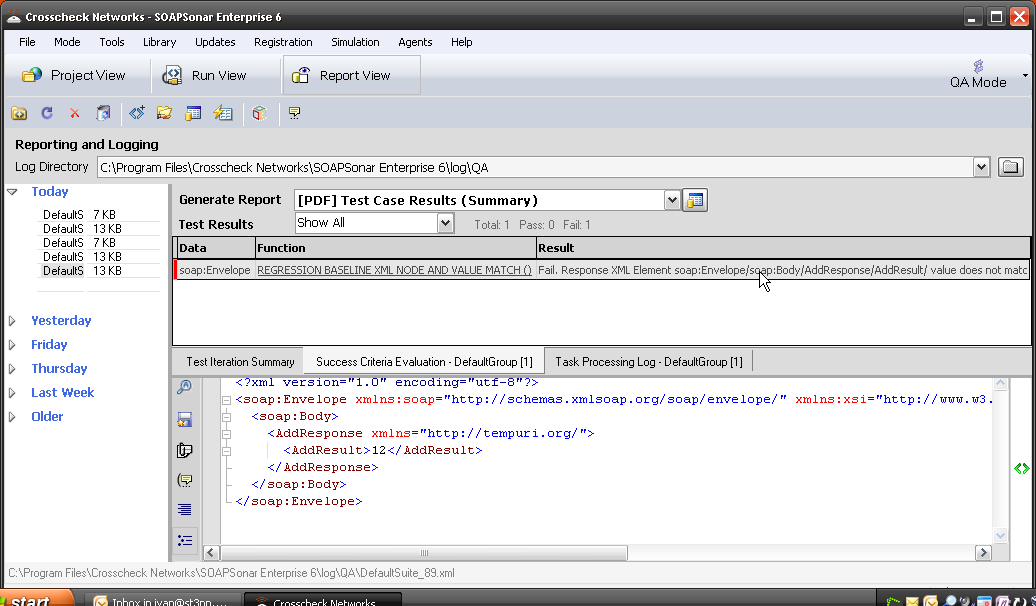
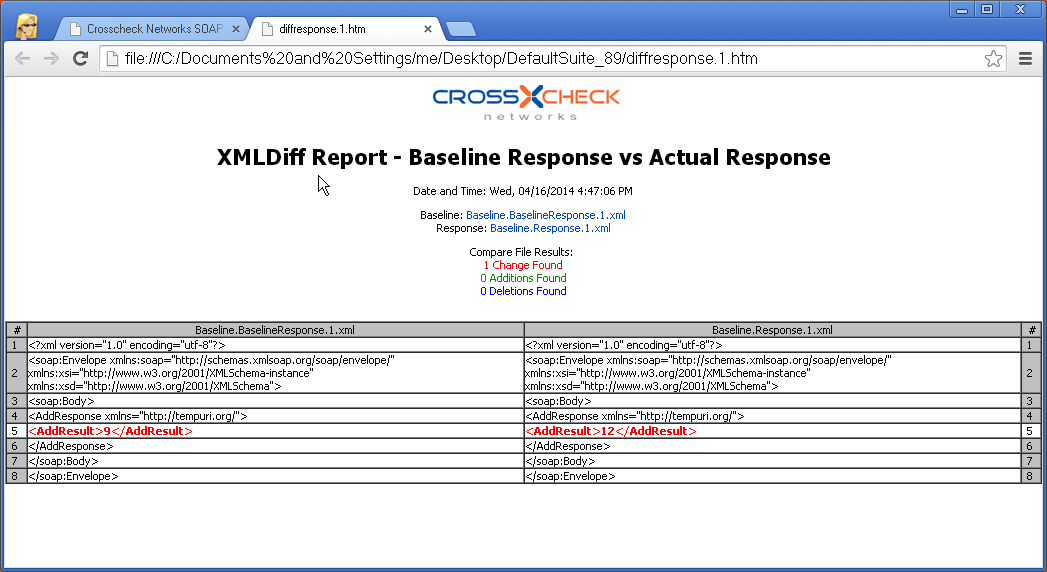
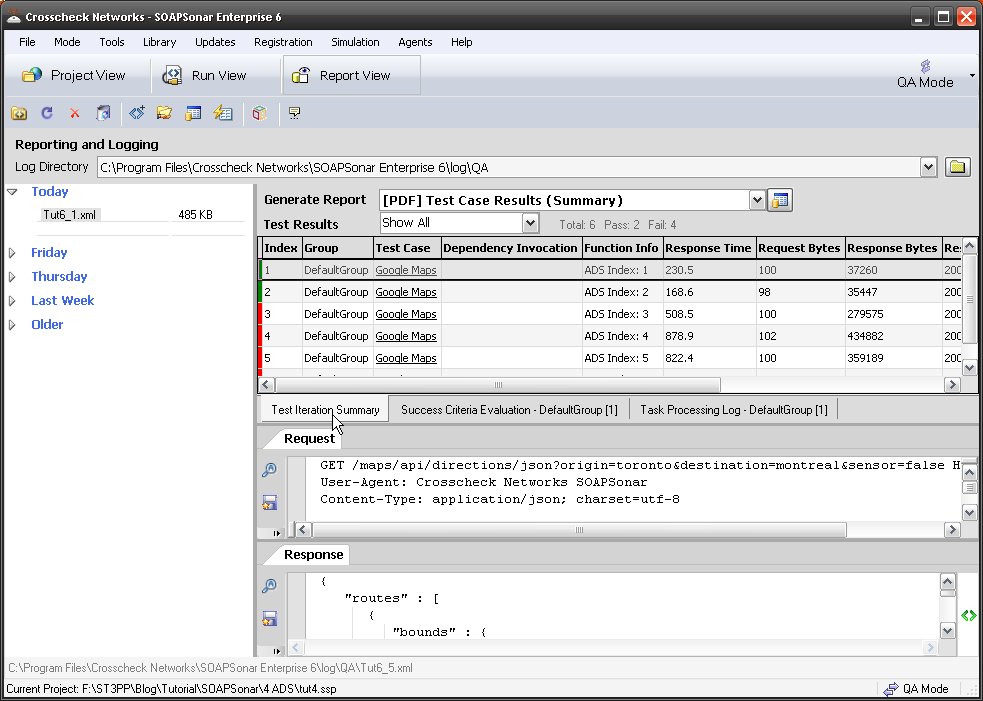
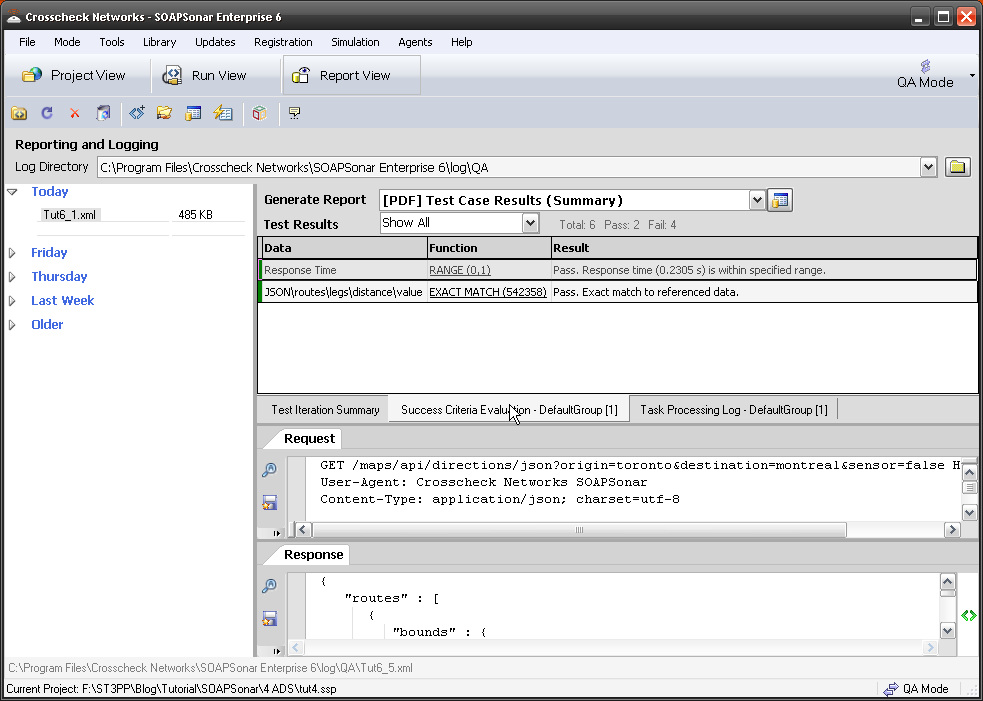
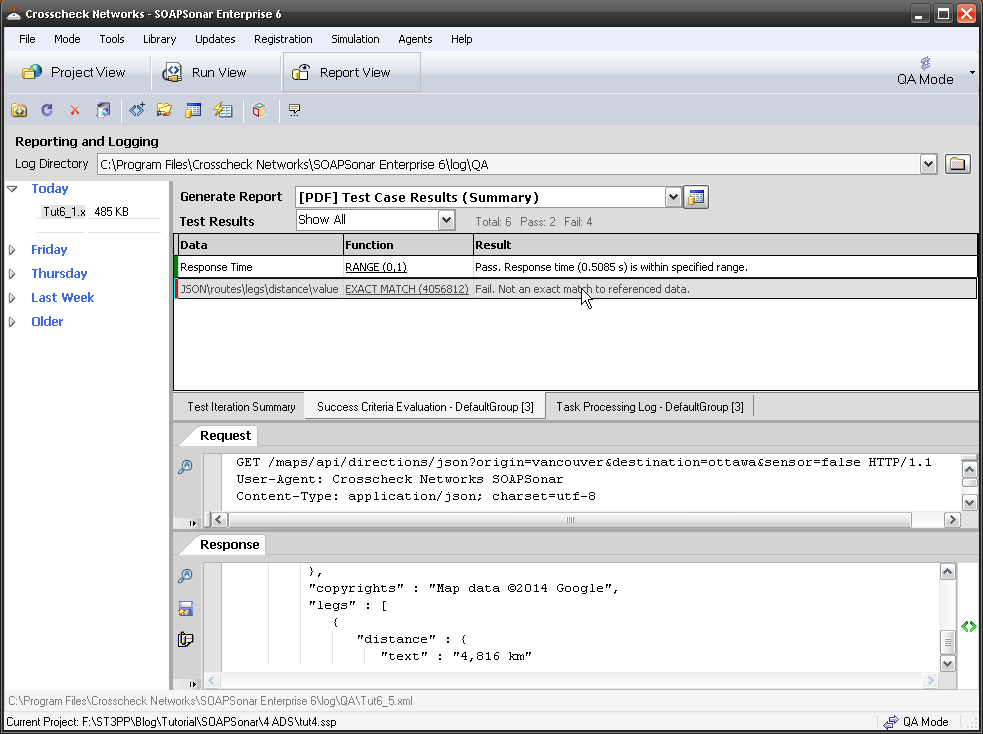
In the Data Economy, the need for each field in each API to be functional still exists. Since API are no longer being developed for a particular client, and independent method of testing the API to ensure no functionality, format or other limitation exists in the API. Automated testing using broadest possible data sources can further ensure Robustness.
2) Compliance Testing
Developing an API, for unknown Consumer applications requires that the API meet with certain standards, to avoid versioning based on client applications. Testing of the API needs to include the compliance of the API to accepted standards in order to ensure that a new Consumer, perhaps for a new native smart phone application, will operate in the same way a web browser client in Chrome does or another server refining the information.
3) Security Testing
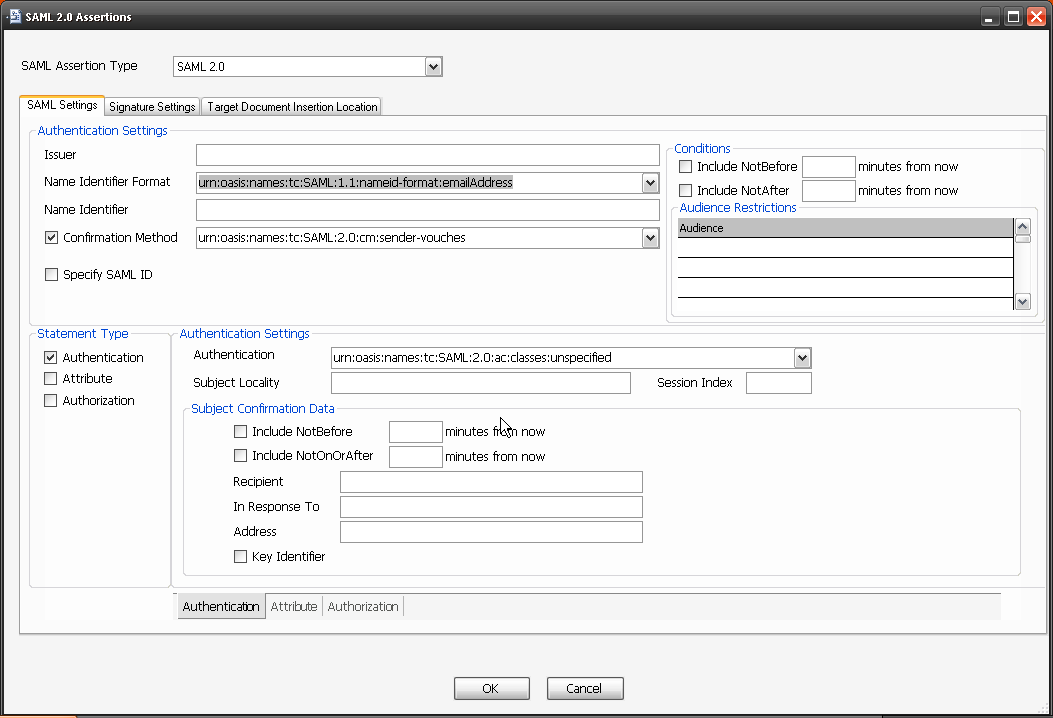
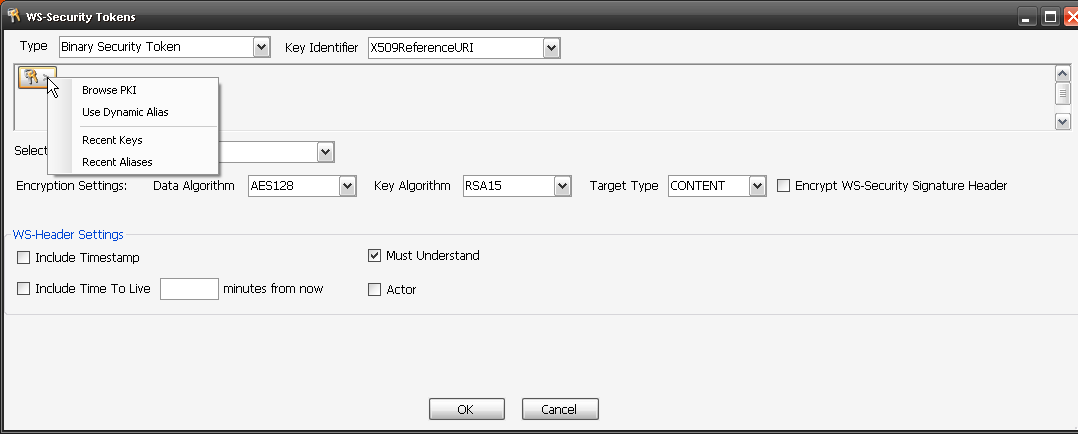
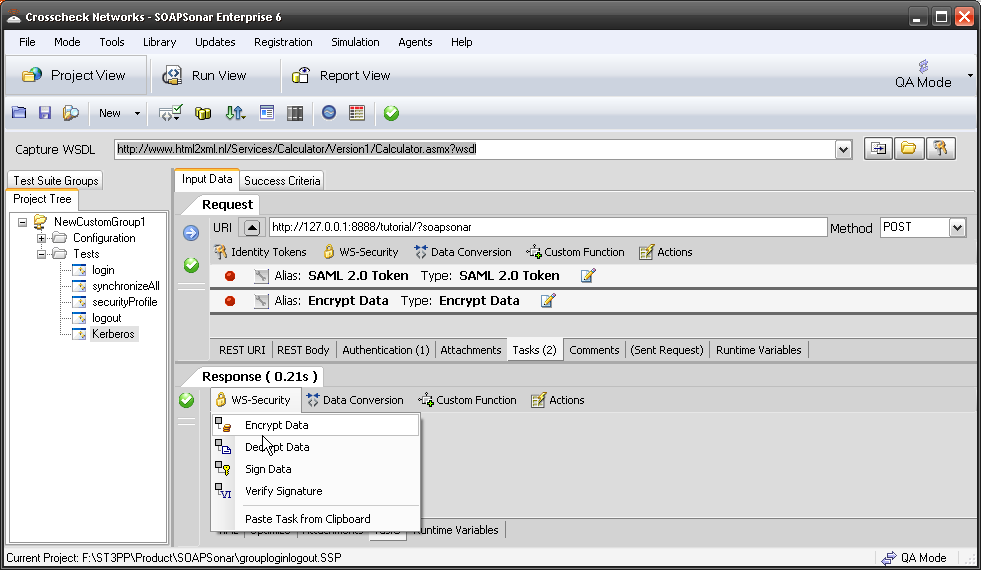
Robust API needs be secure API, independent of client application Consuming the API. SQL Injections, Cross Scripting, Improper key or session management and other OWASP top 10 vulnerabilities need to be tested for. “Cloud” Identity structures like WS, SAML and OAuth along with key management become key components of testing for Robustness. Additional information leakage though API’s with “forgotten” exposed information fields and Metadata can be filtered using a governance gateway.
4) Performance and Scalability
Performance and scalability are not only a function of hardware, but of location, encryption, message signing, network, location, wait times, retries load throttling and many other application design criteria. An application that Consumes information from a variety of API’s on different networks and managed by different teams, requires additional hardening to ensure performance and scalability. How long should I wait if one API is not available? Do I require a resend after how long? What if someone is on a poor quality mobile network, how would that effect my performance? What if I required higher level of encryption? How many concurrent clients can I support with my current infrastructure? What if I split servers or added a second location?
Visionary organizations have started by creating “Information” or “Data Management”executive to extracted value from corporate information for the Data Economy. This involves treating API as we would an application core to the corporations success. Poor quality API, limit access and make extracting value from data near impossible. These executives need to ensure that business, development and QA structure the right process and approach to creating more Robust and Sustainable API.

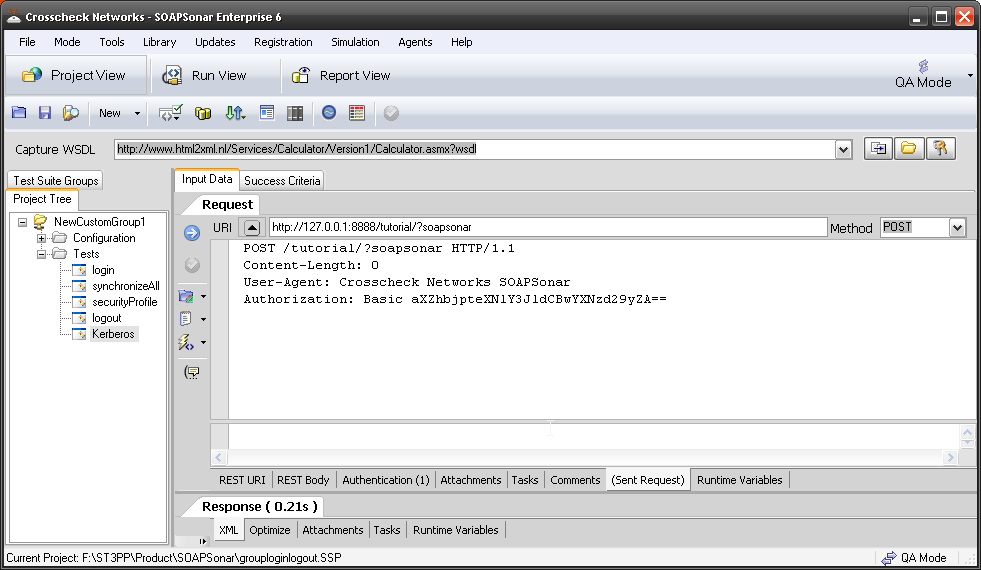
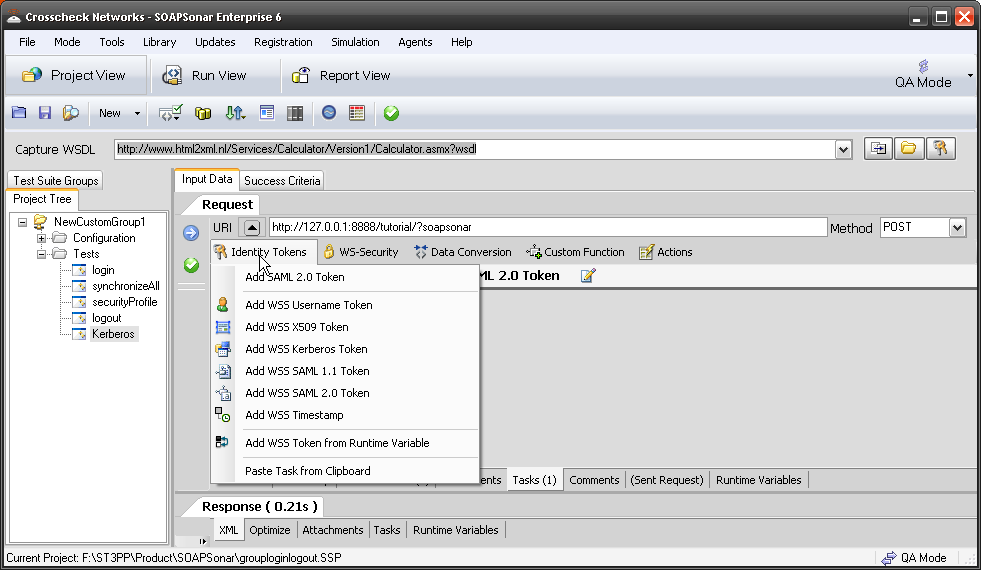
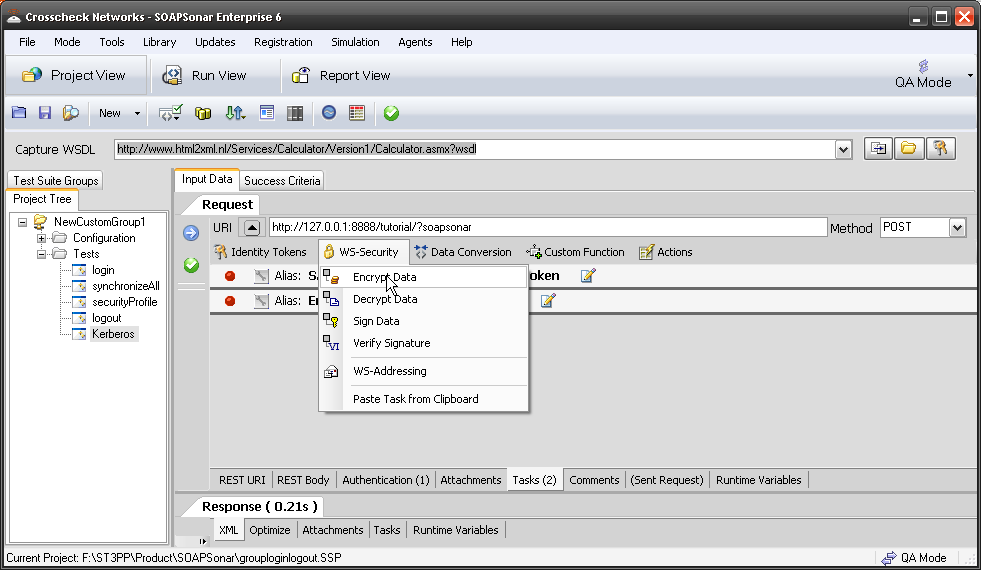
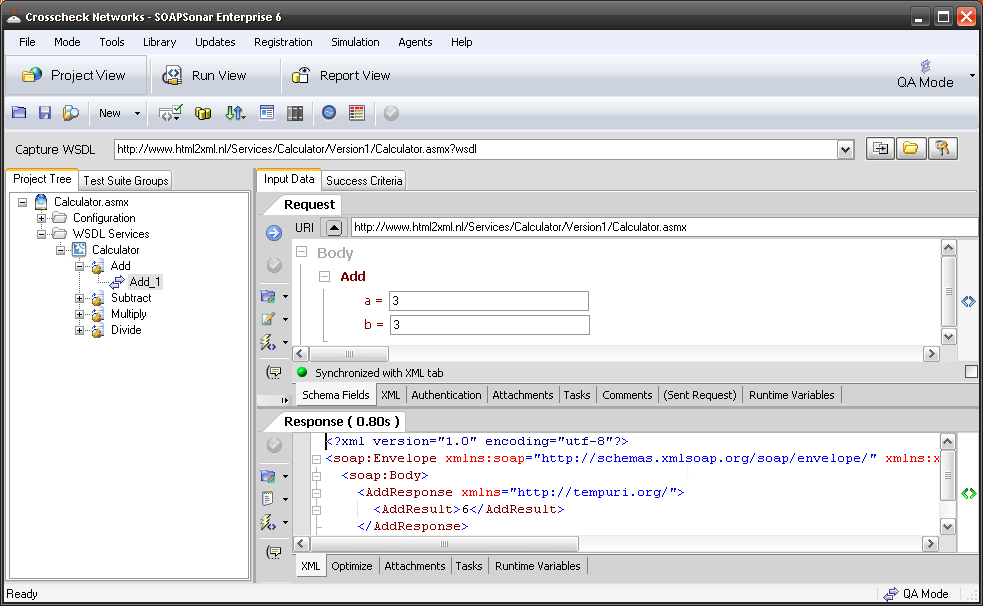
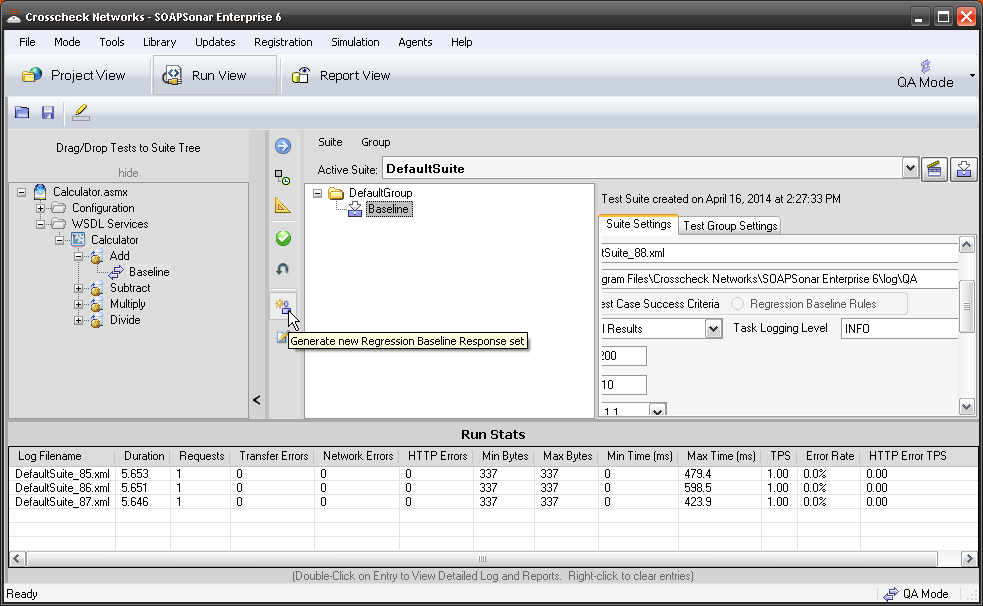
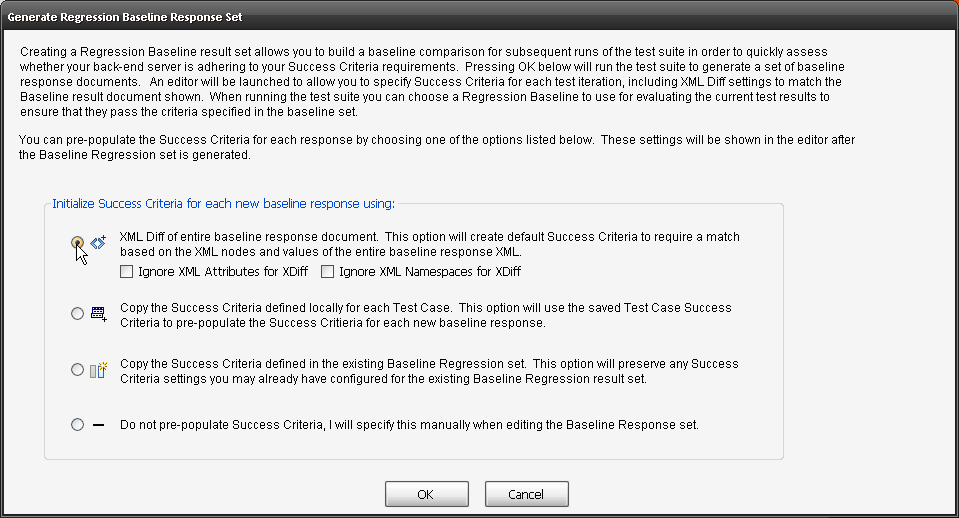
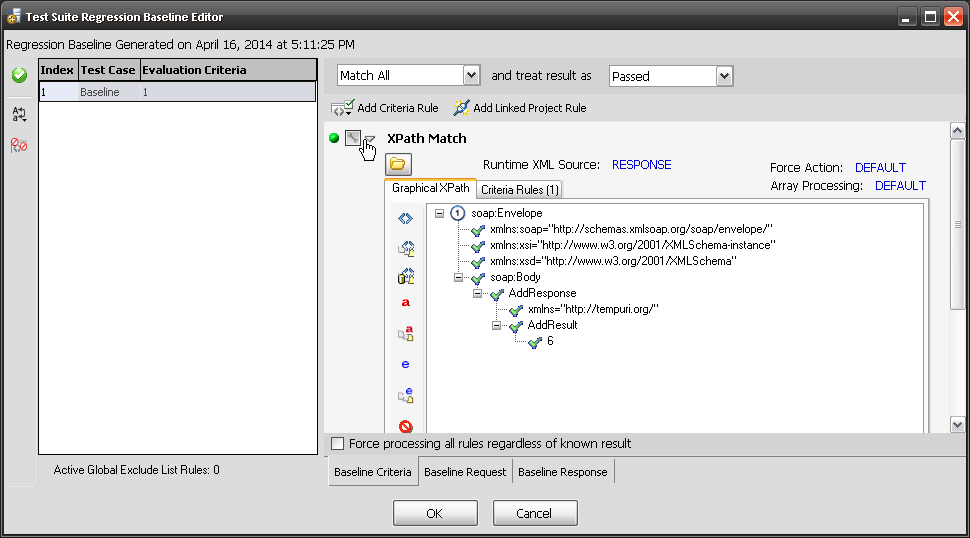
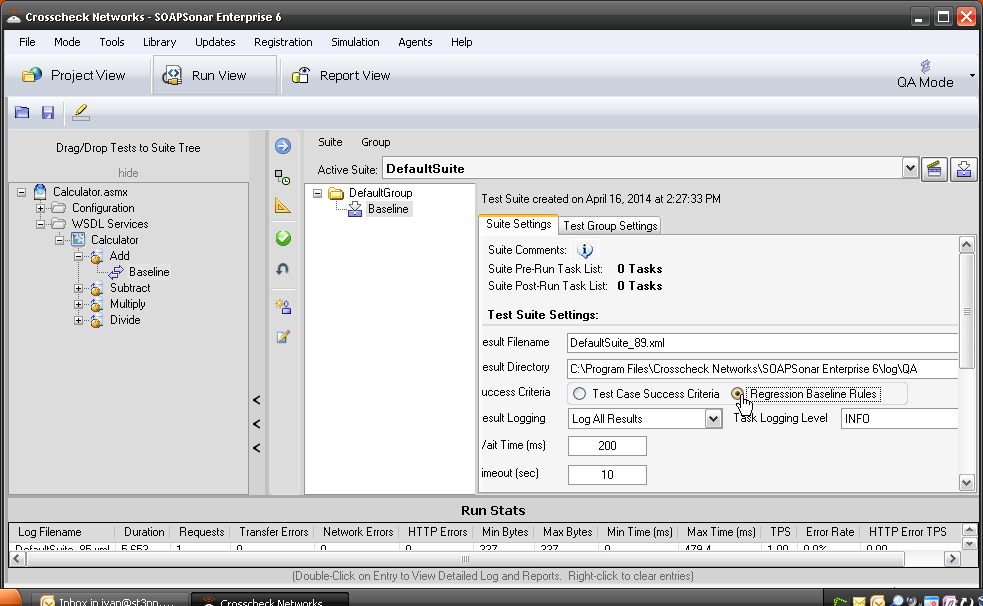
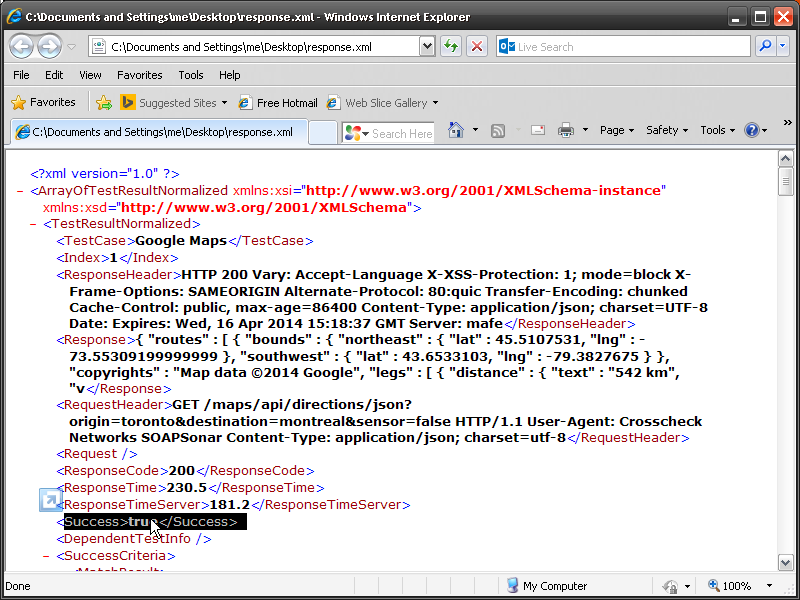
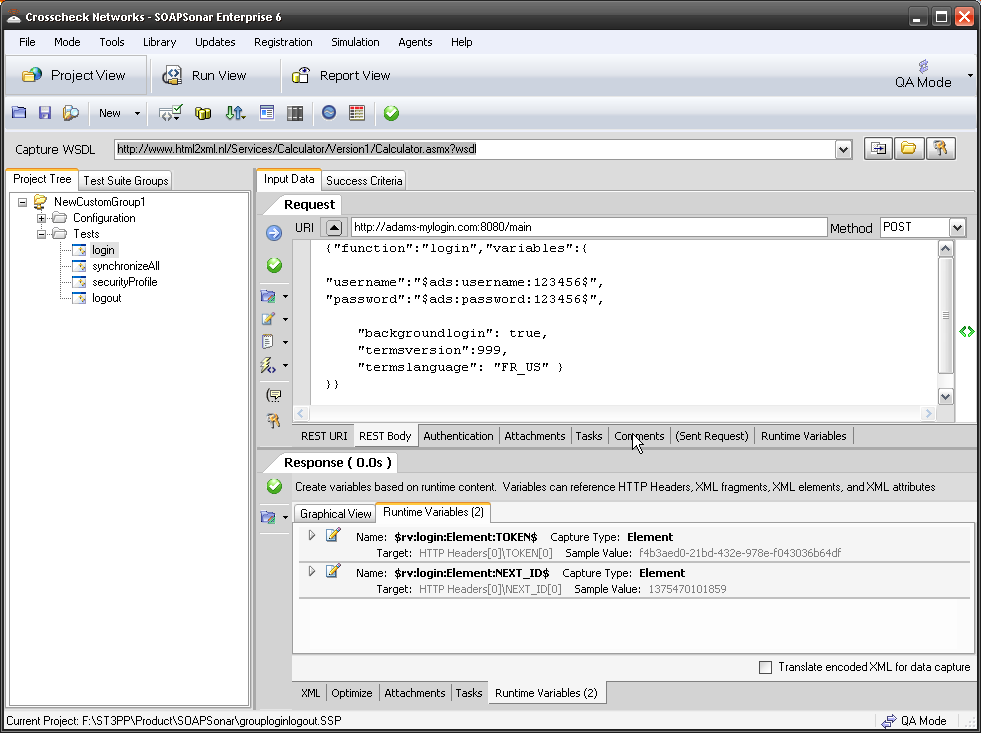 Sometimes identity needs to be in the header. In the request section of SOAPSonar, at the bottom is a number of tabs. By either clicking on the keys icon or the Authentication tab, can see a number of options for configuration. Here you can find Basic, Kerberos, or Digest Authentication settings. You can also set up using the returned cookies and SSL certificates to send embed as part of the header message. (a reminder at the bottom says For WSS-Token SOAP Header Authentication, use the Tasks tab). In the screen below, I selected Basic and entered my username and password.
Sometimes identity needs to be in the header. In the request section of SOAPSonar, at the bottom is a number of tabs. By either clicking on the keys icon or the Authentication tab, can see a number of options for configuration. Here you can find Basic, Kerberos, or Digest Authentication settings. You can also set up using the returned cookies and SSL certificates to send embed as part of the header message. (a reminder at the bottom says For WSS-Token SOAP Header Authentication, use the Tasks tab). In the screen below, I selected Basic and entered my username and password.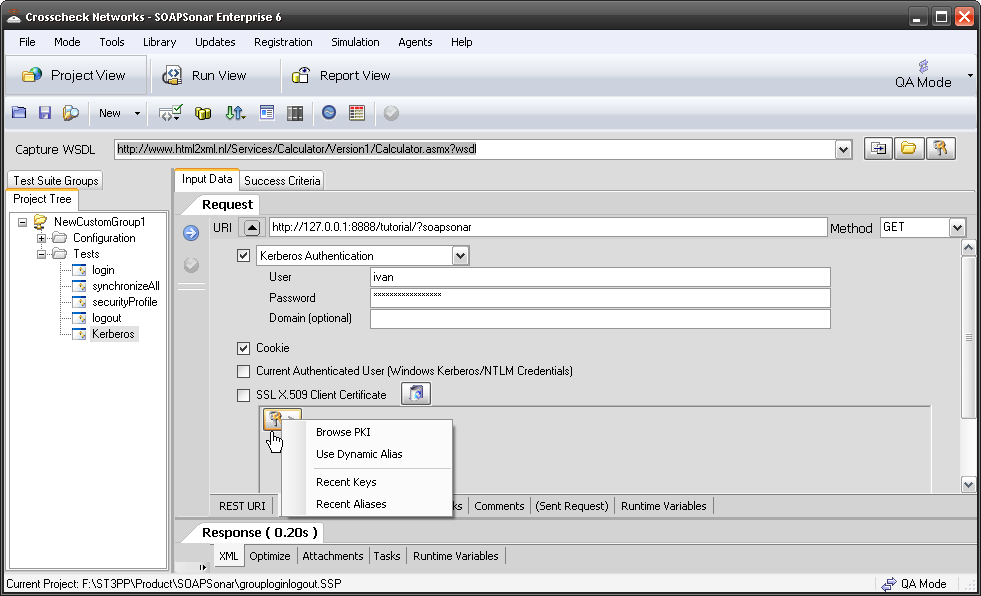



{kind=link}