Calculating Percentage Coverage
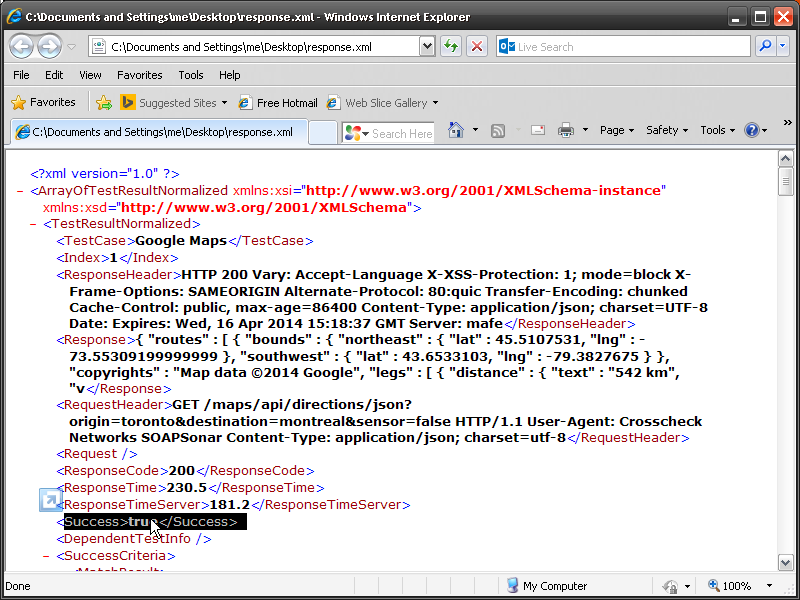
I wanted to discuss some confusion of percentage Test Coverage. I have noticed that different organizations calculate test coverage very differently. This can be very confusing when using contractors, off-shoring and simply comparing best practices. Lets say you have a simple service that returns Name, Phone Number and Address and you asked to create test cases for 100% Test Coverage. What exactly does that mean?
Would a simple unit test entering the following be considered 100% Coverage
- Bob Smith
- 555.555.5555
- 55 street
- City
- QC
- M5M 5L5
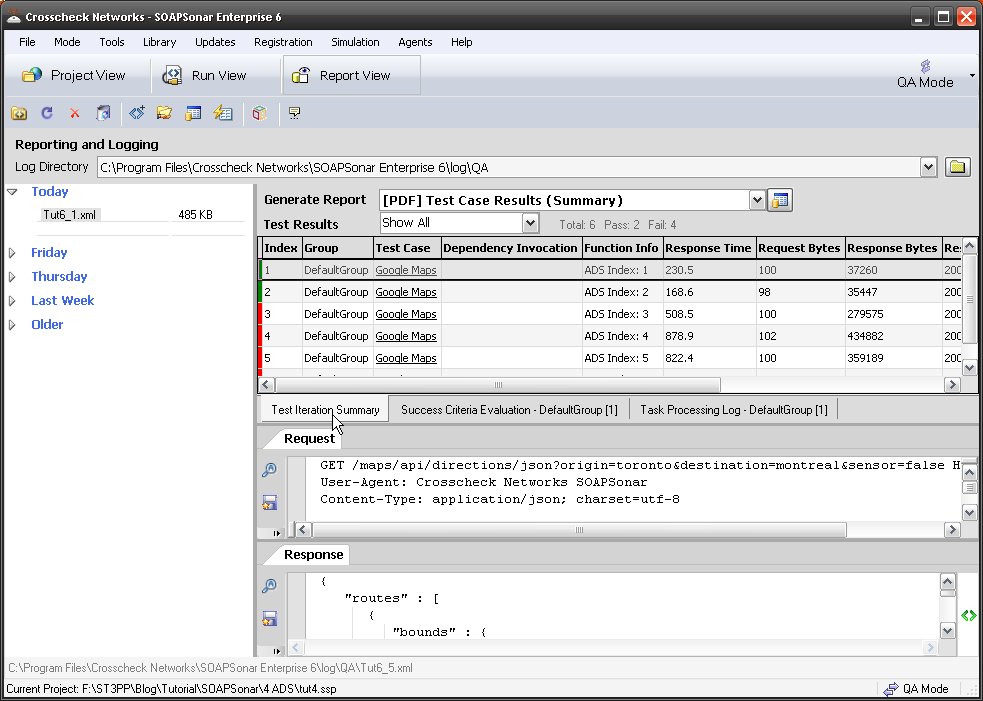
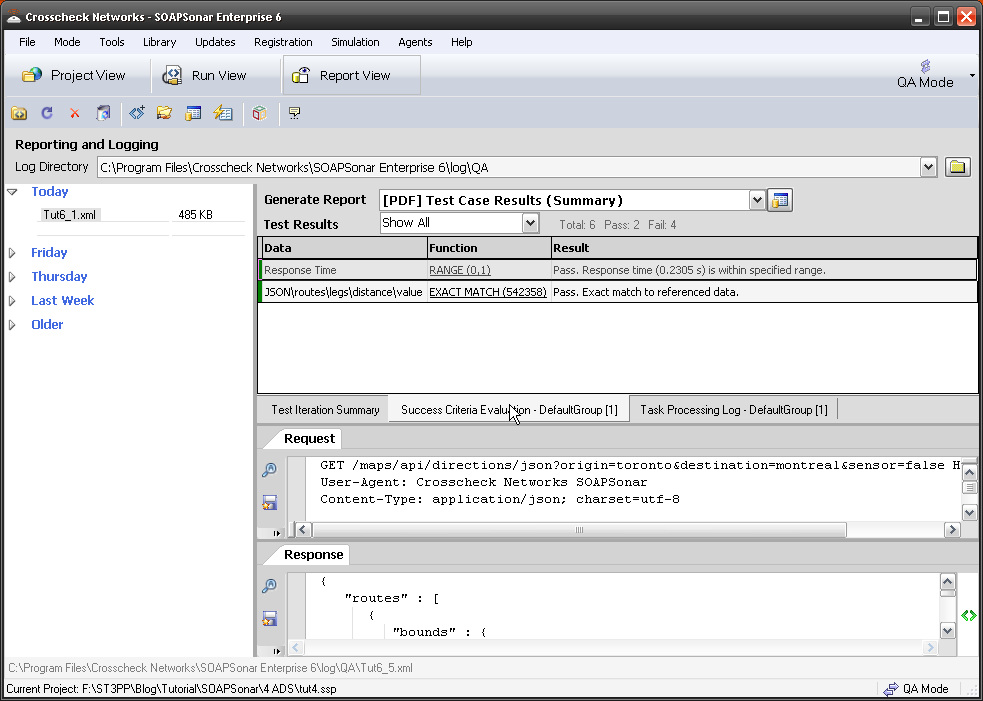
Or would you need to break the service down into each of its functions. Name, Phone Number Street, City, Province, Postal Code. Testing each of these independently?
But how many test cases do you need to perform, for you to consider it 100% coverage. Lets take Postal Codes. Would a single Postal code be considered 100% coverage? Or would you need one from each of the 18 starting letters ( Y, X, V, T, S, R etc)? Perhaps you require some random number of say 10 or 100 postal codes? Or do you need to enter every defined Canadian Postal code. Lets consider testing name function, how long a name does the app need to support, how many names can a person have, what if we include title, what if the persons name has a suffix.
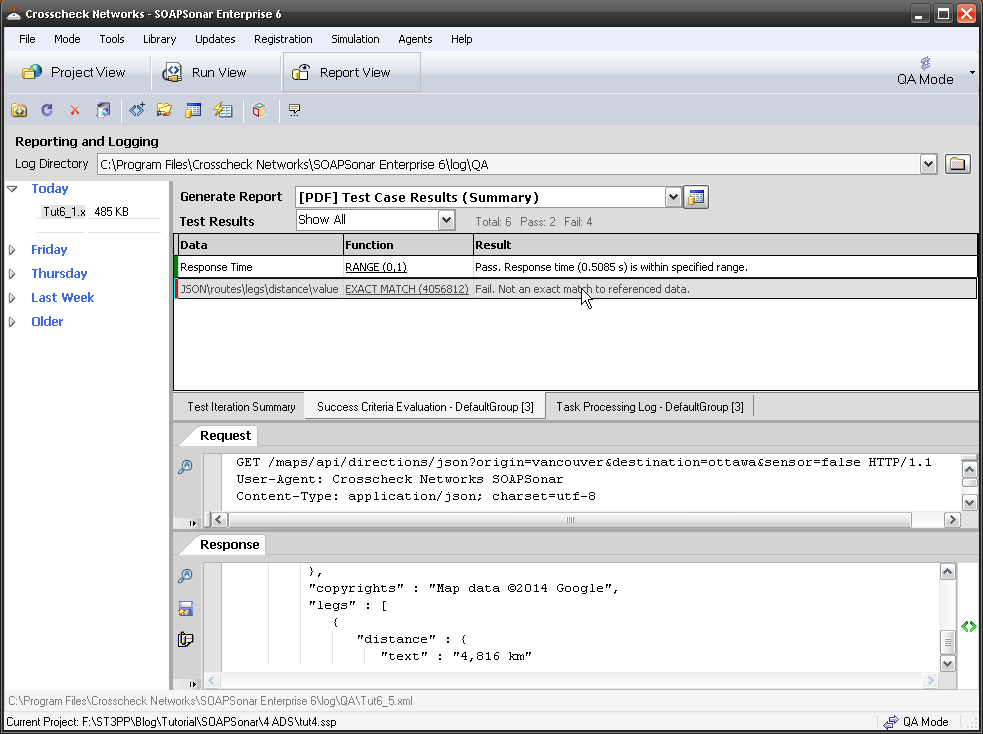
What about negative scenarios? Do you need to test postal code that does not exist, or one in the wrong format before one can consider the test coverage to be 100%? With space after first 3 letters, without space, or with a hyphen. What about letter number letter or what if all letters, number or some other possible combination? How many of these negative scenarios does one need to run to say you covered 100%?
What about testing these functions as they relate to each-other or as this service relates to other services? Do you need to test that a Postal Code starting with letter V, is not used for a city that resides in Quebec? Do you need to confirm that this address service when used in one chained request, responds the same was as when used in another? So often I hear of companies unit testing services as they developed, but never running a final systems and integration end to end test. What if one service requires that postal code to have a hyphen and the other a space?
Understand if your organization is manually testing a service, entering even 18 postal codes will take significant time directly impacting costs. Entering all positive, negative scenarios including chained services is just not feasible. Does increasing the number of test cases actually effect the percentage coverage, or is a single test case enough? All the possible boundaries for a simple service like postal codes could result in a large number of tests. Does testing each service once, without considering all the boundaries and negative scenario’s constitute 100% coverage? More importantly perhaps, is when QA testers give a percentage coverage, does it really mean the same thing to the everyone?
I would like to invite everyone to weigh in and share their thoughts on the subject. Please select and option and comment if you will below. So far the majority selected test every function once. So I broke this into boundaries and positive and negatives to see if we can get further clarification.
***Please note The form is submitted privately and is not automatically published. If you wish your response published, use the comment link at the end of any post***
Warning: strpos() expects parameter 1 to be string, array given in /home/content/13/11164213/html/ST3PP/wp-includes/shortcodes.php on line 193
[contact-form to=’[email protected]’ subject=’percentage coverage’][contact-field label=’What does your Organization consider 100%25 Test Coverage?’ type=’radio’ required=’1′ options=’Whatever We have Time for,One Test for Each Service,Test Each Function of the Service only once,Boundaries for Each Function,Both Positive and Negative Boundaries for Each Function,All/Many (Data Source) in Chained Workflow’/][contact-field label=’Comment’ type=’textarea’/][contact-field label=’Screen Name’ type=’name’/][/contact-form]