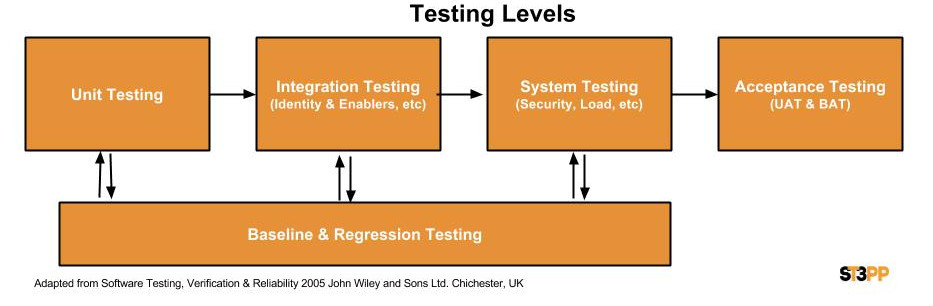
4. REDUCING SCOPE – Test Cycle Strategies
In the service plan costing model, we set the number of Test cases at 20,000. The first post in this series was a introduction on ways to to try and reduce that number. This the 4th in the series follows SDLC Strategies and Test Iteration Strategies and is part of ST3PP’s Best Practice Series aimed at developing better Tools, People and Process. Looking at ways to improve QA efficiency in Canada in order to remain competitive at our higher wages.
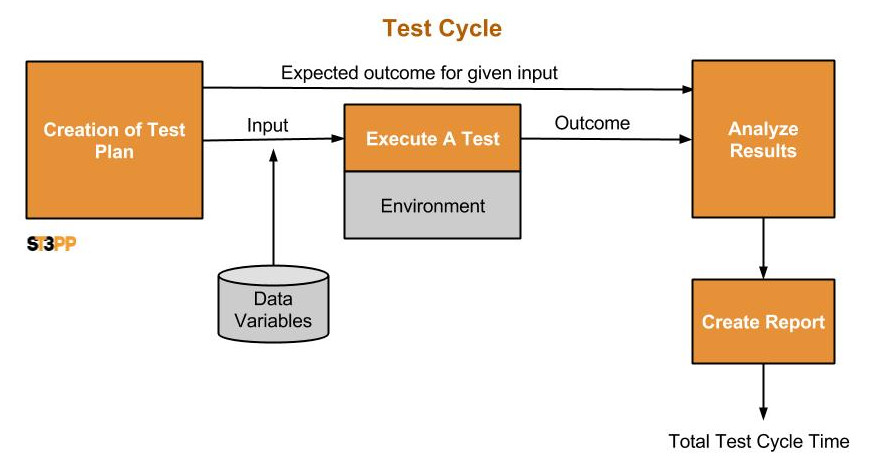
The easiest way is drop something out of the testing. Decrease the percentage coverage, don’t write test plans, test only simple scenarios or don’t create reports. Rather than reducing coverage, lets look at how we reduce effort in running a tests while maintaining quality.
1. Reuse
Reuse is the comes from the idea that if you create a test plan, execute it for a given environment, analyse the results and create a report, then there should be no benefit repeating the exact same test. On the other hand, if there is a code or environment change, that test (and only that test) should not need to be created again, but executed again, and results analysed and reported.
In our service plan costing model, we used 500 services and 10 functions per service and 4 tests per function making up the 50,000 test cases. Testing however should begin long before the all the services are developed. Lets say 20% of the services are developed. The first test iteration would only test 100 and not 500 by 10 x 4 or 4,000 tests. You have great developers and only 10% of those tests cases show there are issues development needs to address. Is there a benefit to running the other 90% of successful test cases again in the next release? Probably not, IF you certain nothing has changed. When the next code drop happens, you can just test 100 new services and the 10 changed ones. For simplicity, I never built this into service plan costing model. In part as the impact depends on if you working short AGILE sprints or longer waterfall based code drops. For accuracy though, these are good measurements and KPI to track and build into your model.
An organization structure and process is not always rigid enough to know for certain that a developer did not touch something and the risk is then missing an undocumented change. Enter automation.
2. Automation
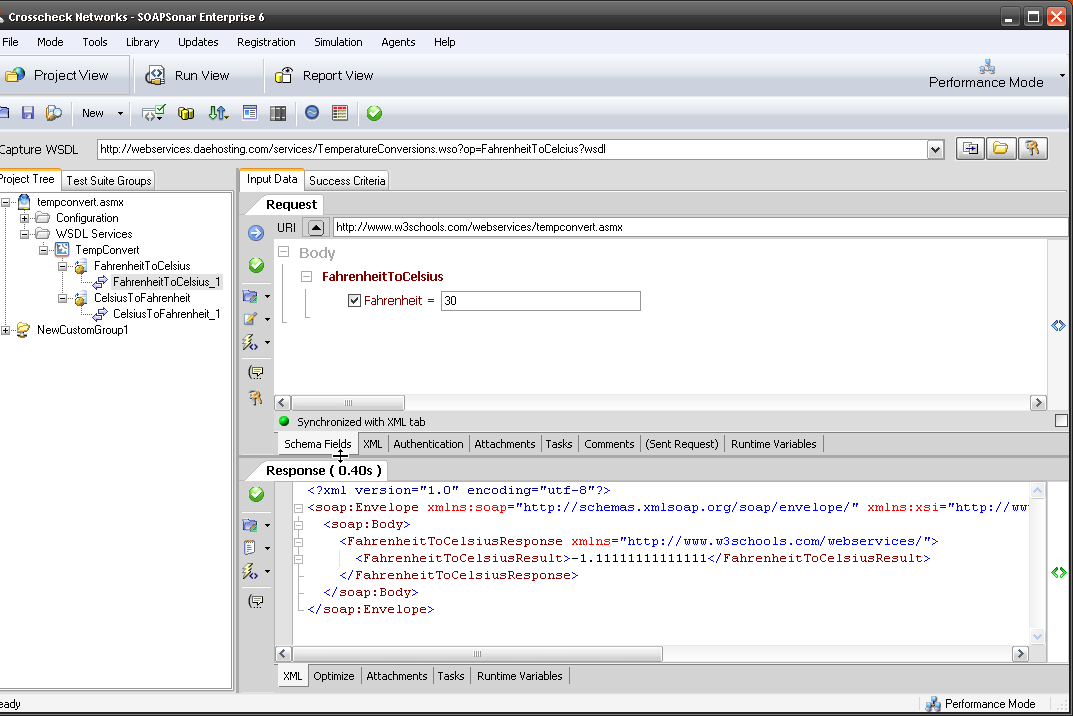
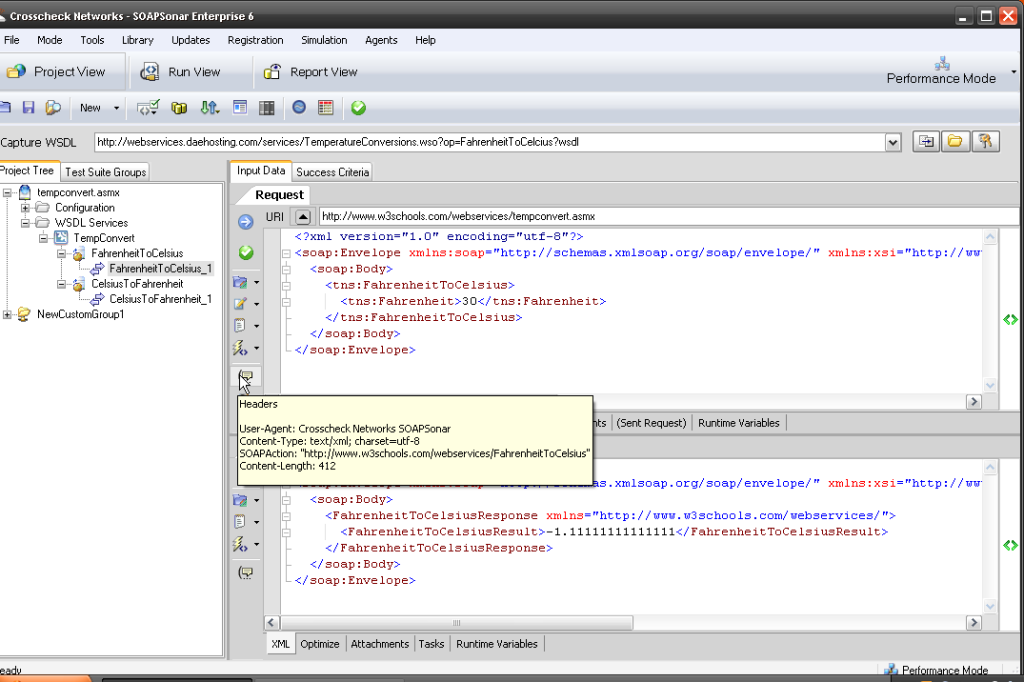
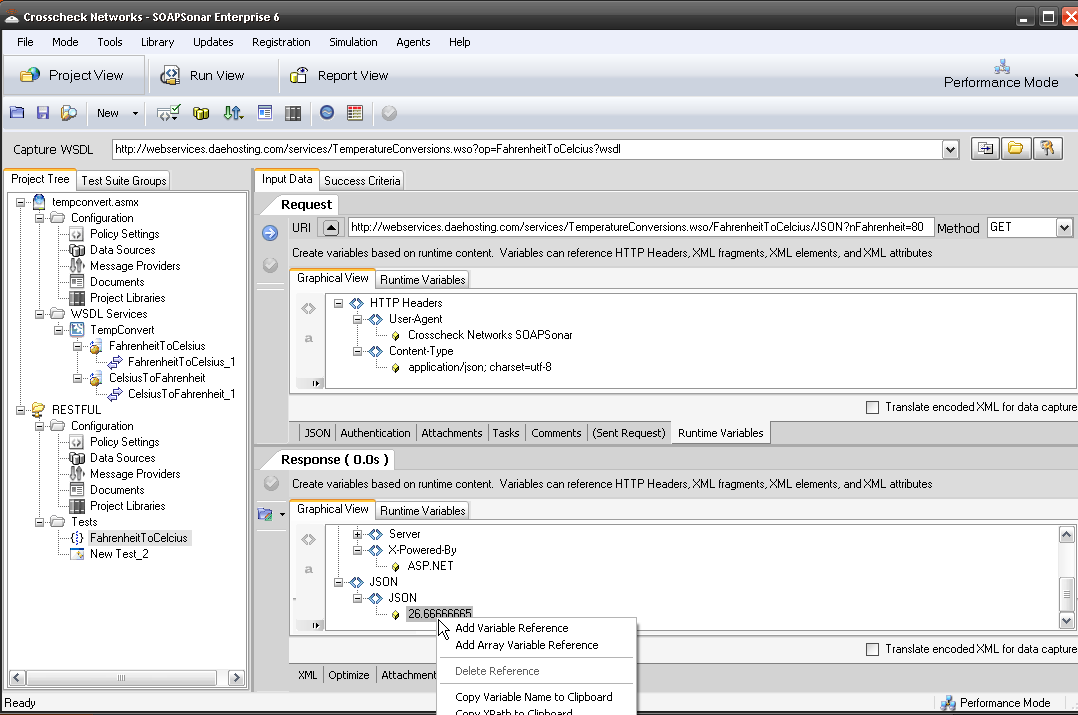
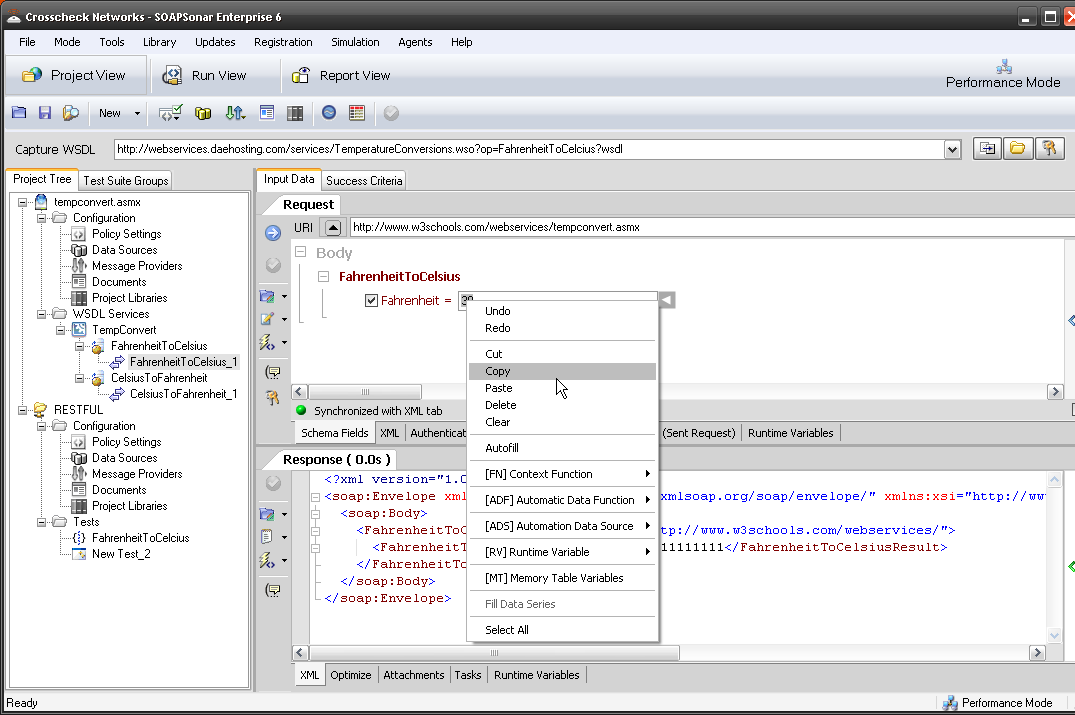
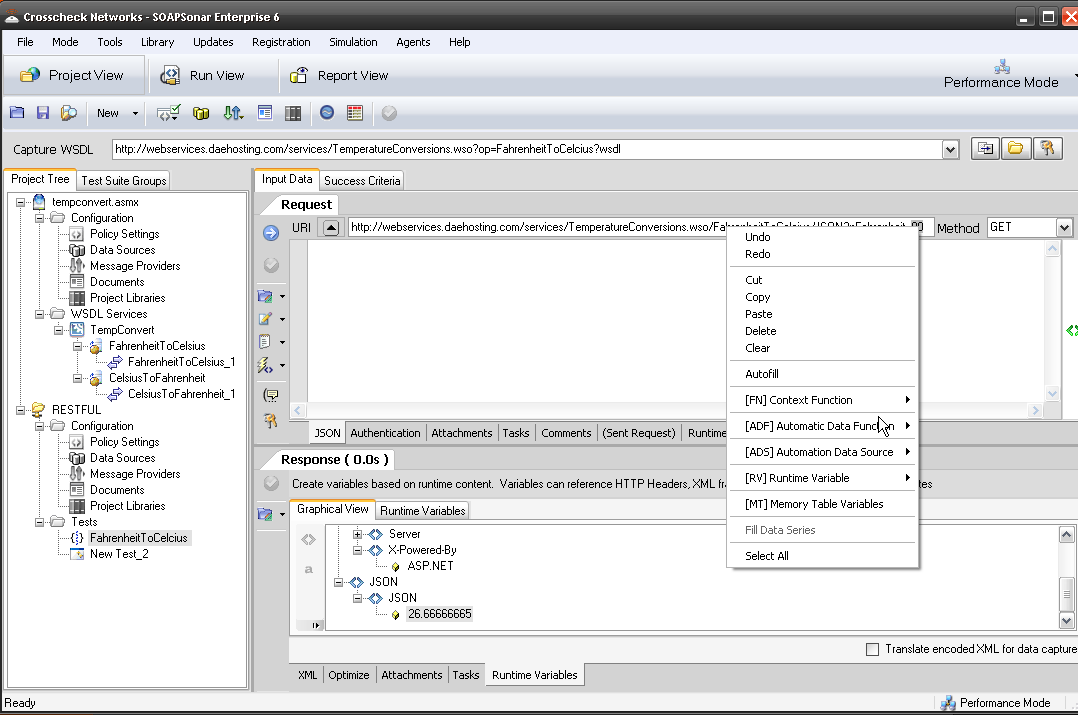
If there is one thing I hear constantly about automation, is that it can take longer to automate and maintain scripts, than it does to manually test. Automation is not the cure for everything. For it to be beneficial it requires changes to your process and approach. Creating the test plan, data sources and success criteria usually take longer with automation, than manual testing, but running the test and generating a report should be far quicker and “automated”. This can mean a single test iteration or cycle, automation can take longer than manual testing. On the other hand, once created, a good automation tool will allow the test to be executed on different , iterations and environments with little or no change, dramatically decreasing the effort. Not all tools are perfect, and redevelopment of the test cases, for the smallest change in code or new test scripts for performance or load can negate the benefits quickly. This is not an automation fault, but that of the tools or process.
Time taken for creating test cases aside, there are other issues automation addresses
- Regression testing (have you tried without automation?) How exactly are you sure you not missing an undocumented change?
- How do you plan on continuous testing a service without automation?
- Need to run through a thousand variables, how long will that take manually execute these tests?
- How long does it take to execute an automated test, once already developed vs a manual?
- What does executing (not creating) a automation test costs in man hours?
- What about testing after launch in the SDLC, will you do that manually?
- Do automation QA testers really cost more?
To be fair to automation, one needs to compare the impact of automation with on the entire SDLC, utilizing automation with a suitably redesigned process. If then the effort is not worth the reward, it’s a lesson learnt. Not every project will be suited to automation
Conclusion
A final note on documentation, test case development and reporting documentation are often the biggest time consumers of testing. Time equalling cost. Documentation needs to balance detail with effort. Ironically, I spent a chunk of time this morning reading through a 37 page test plan. Yet on looking to implement the first test case, I found the a required parameter not mentioned anywhere in the 37 pages. I then looked at a different test plan, and it was not there either, yet found it in seconds in that tools automation test script.
Fundamentally we are looking for ways to save time focussing on the areas of highest impact. Its not about slavishly following a set process, but defining the process to be more effective and hence increasing our value and software quality.